关于缺失值个数的统计问题 求大佬解答
-
而且在最里面定义函数和绑定,有啥用?

-
@kidswong999 a是把img.draw_cross(iris[0], iris[1])里的数据提取出来 用来检测瞳孔识别 这个代码对着眼睛 然后你眨眼 打印数据就会丢失 丢失的个数就是眨眼次数
-
很奇怪,建议你换一个思路。
if iris 就是判断是否有眼睛。
-
你这个思路我们最开始就是这个 但是根本运行不到else那里去
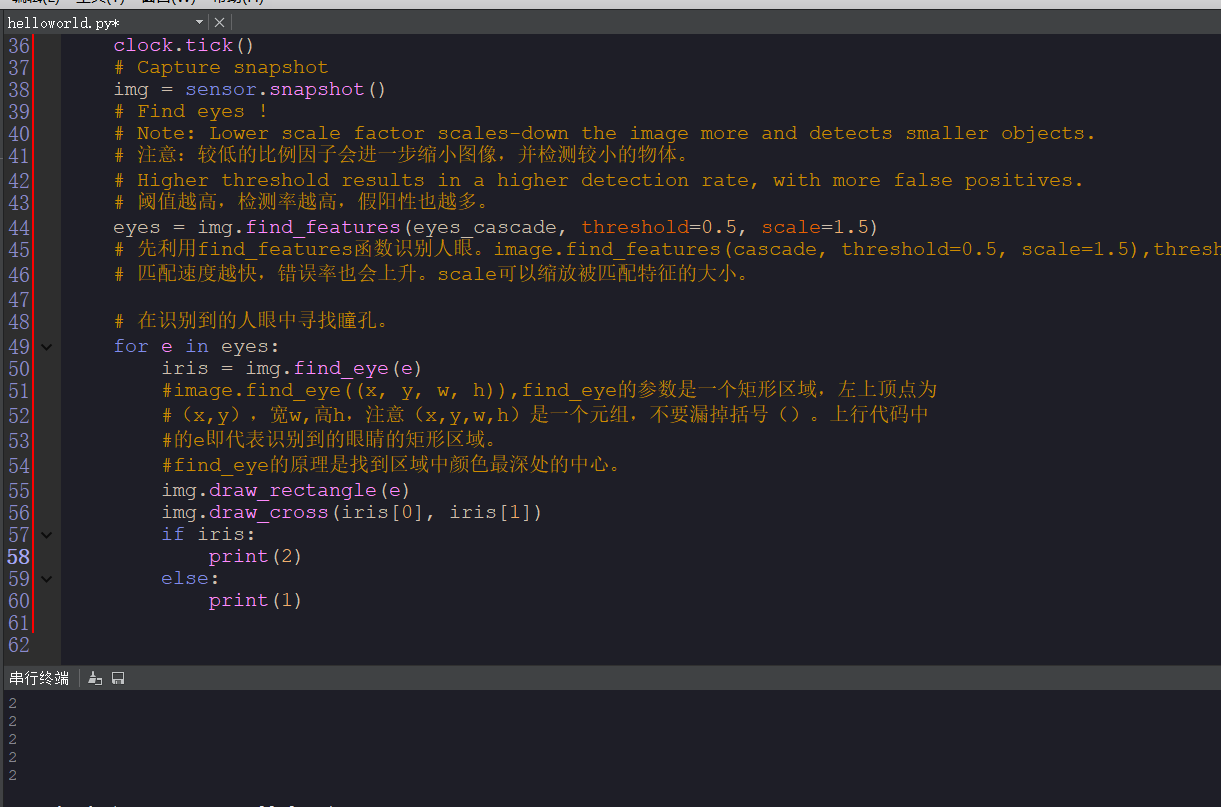
# 瞳孔识别例程 # # 这个例子展示了如何找到图像中的眼睛后的瞳孔(瞳孔检测)。 该脚本使用 # find_eyes函数来确定应该包含瞳孔的roi的中心点。 它通过基本上找到瞳孔 # 中心的眼睛最黑暗的区域的中心。 # # 注意:此脚本首先不会检测到脸部,请将其与长焦镜头一起使用。 import sensor, time, image #重置传感器 sensor.reset() #传感器设置 sensor.set_contrast(3) sensor.set_gainceiling(16) # 将分辨率设置为VGA。 sensor.set_framesize(sensor.VGA) #拉近镜头,使眼睛的更多细节展现在摄像头中。 # 裁剪图像到200x100,这提供了更多的细节和更少的数据处理 sensor.set_windowing((220, 190, 200, 100)) sensor.set_pixformat(sensor.GRAYSCALE) # 加载眼睛的haar算子 # 默认情况下,这将使用所有阶段,较低的阶段更快但不太准确。 eyes_cascade = image.HaarCascade("eye", stages=24) print(eyes_cascade) # FPS clock clock = time.clock() while (True): clock.tick() # Capture snapshot img = sensor.snapshot() # Find eyes ! # Note: Lower scale factor scales-down the image more and detects smaller objects. # 注意:较低的比例因子会进一步缩小图像,并检测较小的物体。 # Higher threshold results in a higher detection rate, with more false positives. # 阈值越高,检测率越高,假阳性也越多。 eyes = img.find_features(eyes_cascade, threshold=0.5, scale=1.5) # 先利用find_features函数识别人眼。image.find_features(cascade, threshold=0.5, scale=1.5),thresholds越大, # 匹配速度越快,错误率也会上升。scale可以缩放被匹配特征的大小。 # 在识别到的人眼中寻找瞳孔。 for e in eyes: iris = img.find_eye(e) #image.find_eye((x, y, w, h)),find_eye的参数是一个矩形区域,左上顶点为 #(x,y),宽w,高h,注意(x,y,w,h)是一个元组,不要漏掉括号()。上行代码中 #的e即代表识别到的眼睛的矩形区域。 #find_eye的原理是找到区域中颜色最深处的中心。 img.draw_rectangle(e) img.draw_cross(iris[0], iris[1]) if iris: print(2) else: print(1)
-
当然不会运行到,因为你在是for循环里面判断的。
-
那您有什么好办法吗 我试了好多好多种
-
@kidswong999 那您有什么好办法吗 我试了好多好多种
-
首先,我不知道你具体要做什么。
-
@kidswong999 就是想在每隔一分钟可以把人眼的眨眼次数给搞出来
-
@guzr 大佬 我这个有办法嘛